Think4Ever Approach vs. Vibe Coding
Executive Summary
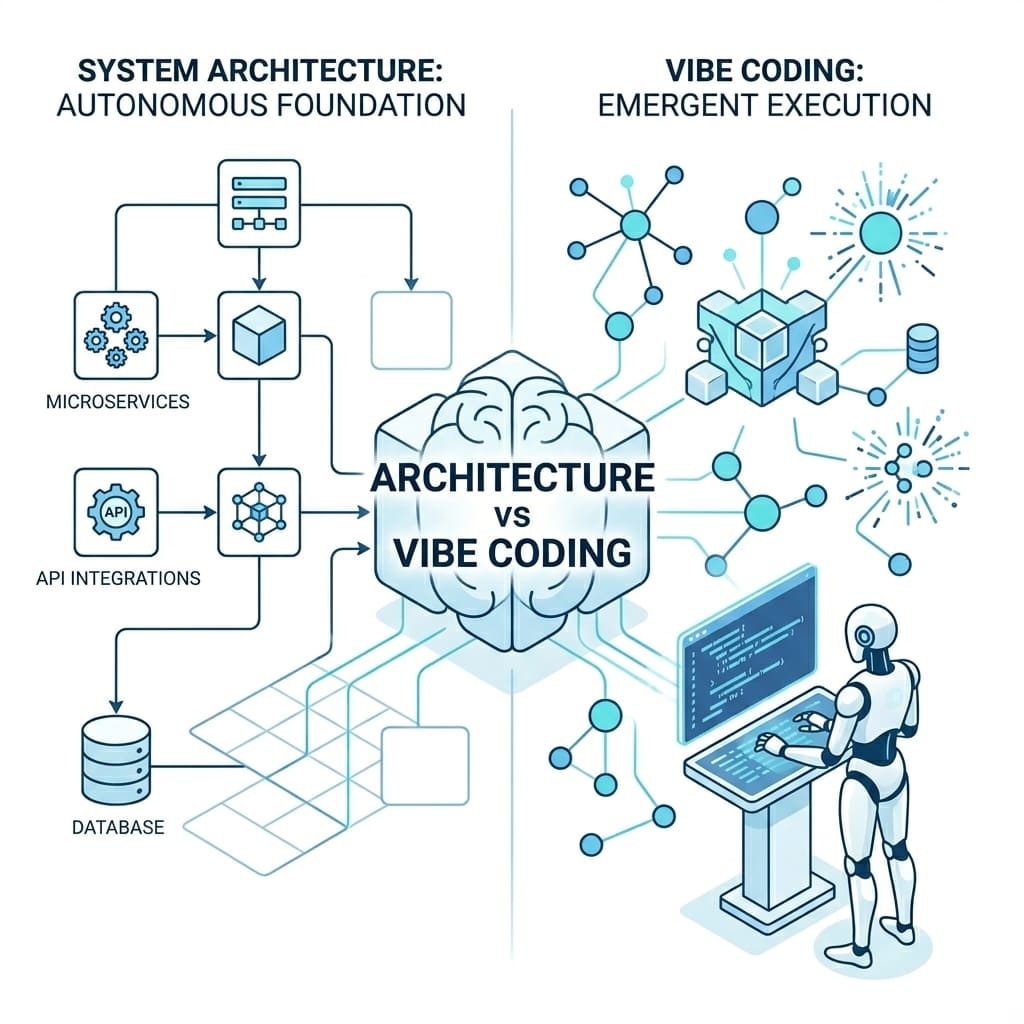
Think4Ever is a design-first, agentic application development platform engineered to move the industry past the era of fragmented AI assistants and into true system-level engineering. First-generation AI coding tools act as point-solution helpers—code autocompletes, copilots, and chat interfaces strapped onto a legacy, disconnected software development lifecycle (SDLC) to help humans type faster.
Think4Ever replaces this piecemeal model entirely. It introduces a unified, autonomous development environment driven by a rigid architectural harness, multi-session context preservation, and built-in security analysis.
Core Capabilities
1. Moving From Copilots to Autonomous System Engineering
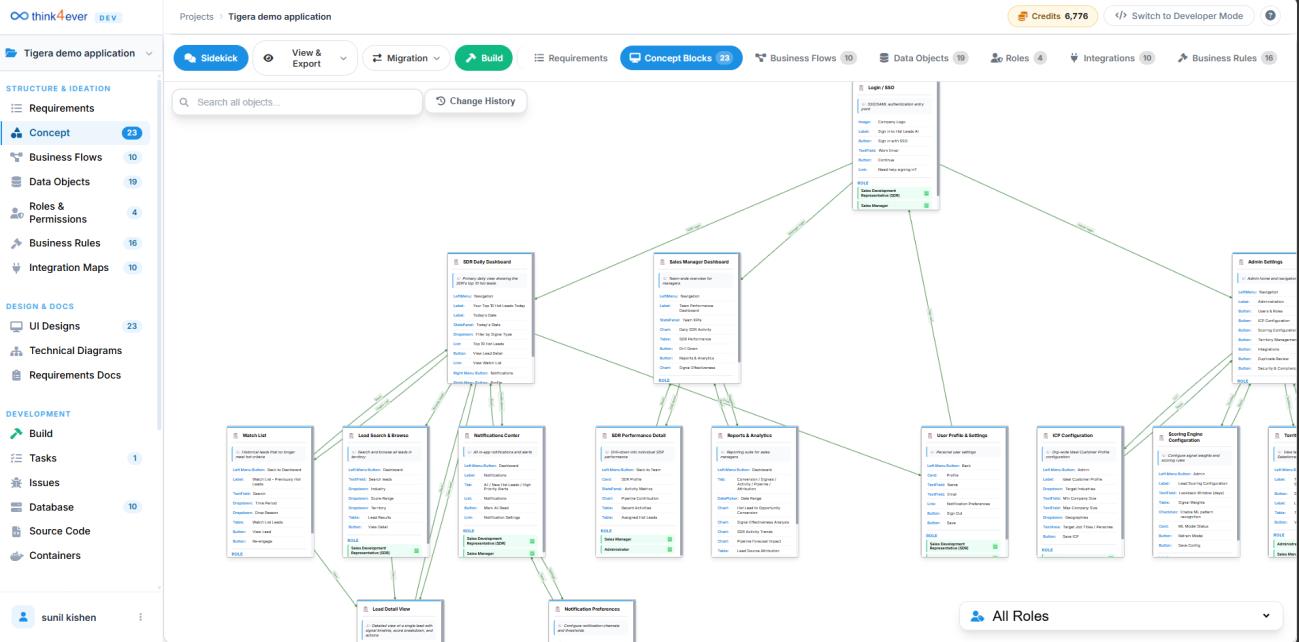
An AI assistant speeds up the generation of raw code blocks, but it doesn't understand the application as a holistic system. Think4Ever abandons this localized approach, using a structured architecture and design harness that maps out the entire product lifecycle before code generation begins. The platform enforces deep system-level coherence across every phase:
- Concept to Schema: Translating business requirements into strict domain models.
- Deterministic Blueprinting: Generating clear technical specs that guide downstream coding agents.
- The Structural Harness: Ensuring that as the application grows, code cannot "drift" away from the core architecture or collapse into unmaintainable spaghetti.
2. Eliminating the Context Window Bottleneck
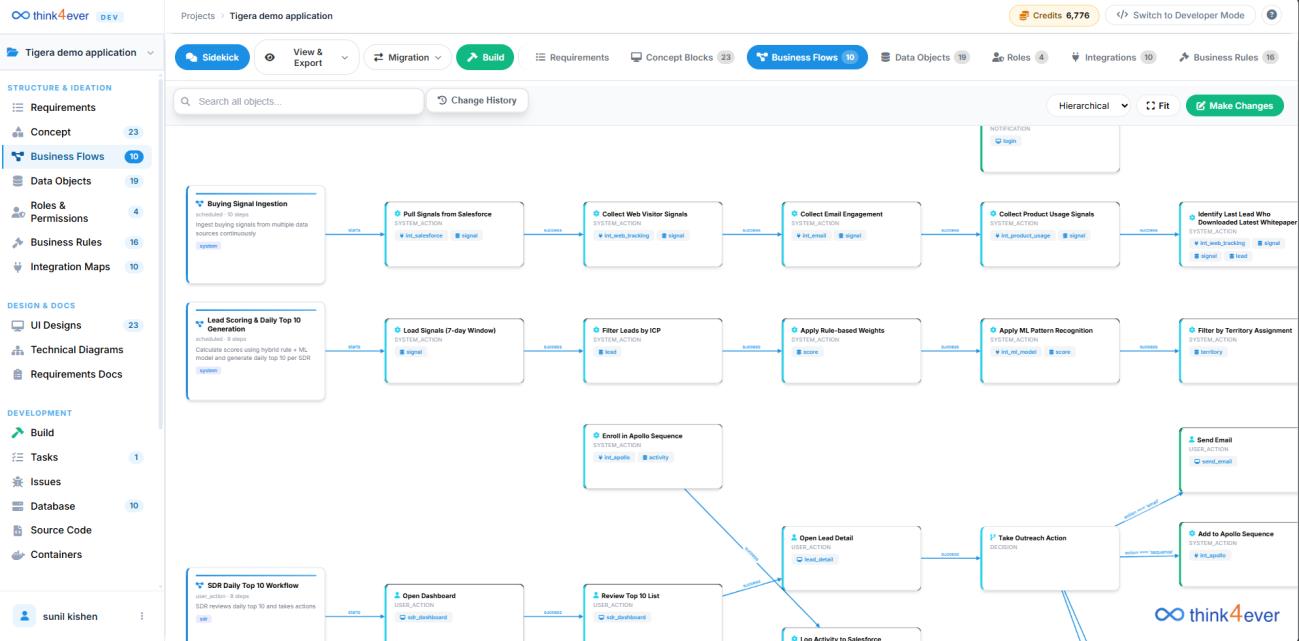
Traditional AI assistants suffer from context collapse—the larger a codebase grows, the more the AI forgets earlier decisions, resulting in broken dependencies and fragmented logic. Think4Ever solves this with proprietary multi-session context preservation. Instead of cramming raw files into a temporary LLM chat window, the system maintains a persistent, structured graph of the entire application state. Whether you are adjusting an API contract on day one or refactoring a checkout workflow in month six, the platform retains an uncompromised, system-wide understanding of the product.
3. Token-Efficient, Deterministic Execution
Relying on an LLM to repeatedly read and rewrite massive code repositories is slow, costly, and inherently error-prone. Think4Ever introduces highly optimized token-efficient LLM interactions. By routing AI generation through the underlying design harness rather than parsing raw text code continuously, the platform achieves ultra-precise, highly localized code execution. This radically lowers latency, prevents context window degradation, and ensures predictable, deterministic code output.
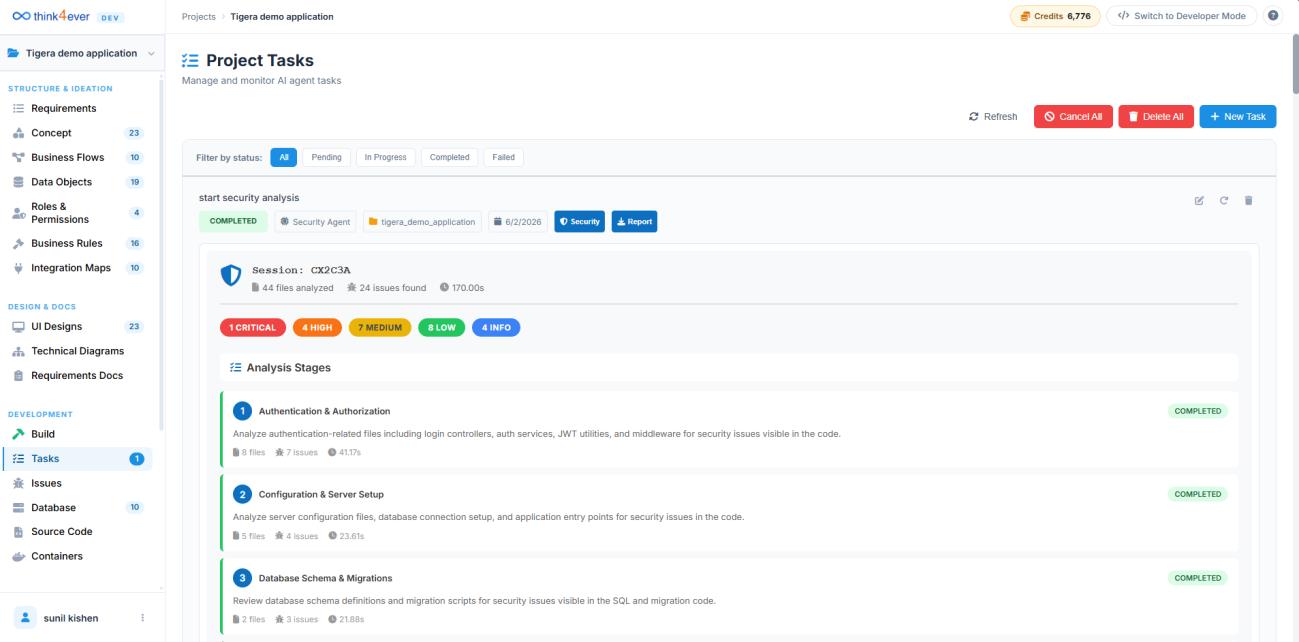
4. Security Analysis
In a world of rapid AI code generation, security cannot remain a post-export cleanup task or an external manual audit. Think4Ever bakes enterprise-grade compliance directly into the core compilation loop. The platform runs comprehensive security analysis and recommendations for fixing security issues alongside automated code execution. It actively scans for vulnerabilities—such as injection vectors, broken object-level authorization (BOLA), and data leakage risks—flagging and resolving them before the application ever reaches a staging environment.
The Structural Shift in Application Development
Operational Model
01A faster keyboard; assists humans in writing code file-by-file.
An autonomous engineering engine driving the entire SDLC from spec to deployment.
System Visibility
02Fragmented; reads local file contexts but lacks architectural awareness.
Absolute; maintained via a persistent design harness and system-level coherence.
Scalability Limit
03Hits a wall when codebase complexity outgrows the LLM context window.
Infinite vertical scale via multi-session context preservation and graph-based state tracking.
Resource Efficiency
04High token waste from constantly feeding raw repository files back to the LLM.
Ultra-low token consumption via targeted, harness-guided code execution.
Security & Trust
05Reactive; relies on external scanners or human code reviews after generation.
Proactive; native security analysis is a mandatory gate in the compilation loop.
| Engineering Vector | The Point-Assistant Approach (Cursor, Lovable, Bolt) | The Think4Ever Autonomous Approach |
|---|---|---|
| Operational Model | A faster keyboard; assists humans in writing code file-by-file. | An autonomous engineering engine driving the entire SDLC from spec to deployment. |
| System Visibility | Fragmented; reads local file contexts but lacks architectural awareness. | Absolute; maintained via a persistent design harness and system-level coherence. |
| Scalability Limit | Hits a wall when codebase complexity outgrows the LLM context window. | Infinite vertical scale via multi-session context preservation and graph-based state tracking. |
| Resource Efficiency | High token waste from constantly feeding raw repository files back to the LLM. | Ultra-low token consumption via targeted, harness-guided code execution. |
| Security & Trust | Reactive; relies on external scanners or human code reviews after generation. | Proactive; native security analysis is a mandatory gate in the compilation loop. |
Summary
The Structural Reality: Traditional AI coding tools are built to help engineers manage legacy development habits slightly faster. Think4Ever is the winning platform archetype—built from the ground up for an era where the AI doesn't just help you write the code, but handles the architecture, execution, context preservation, and security of the entire enterprise software ecosystem.